Search, as we know it, has been irrevocably changed by generative AI.
The rapid improvements in Google’s Search Generative Experience (SGE) and Sundar Pichai’s recent proclamations about its future suggest it’s here to stay.
The dramatic change in how information is considered and surfaced threatens how the search channel (both paid and organic) performs and all businesses that monetize their content. This is a discussion of the nature of that threat.
While writing “The Science of SEO,” I’ve continued to dig deep into the technology behind search. The overlap between generative AI and modern information retrieval is a circle, not a Venn diagram.
The advancements in natural language processing (NLP) that started with improving search have given us Transformer-based large language models (LLMs). LLMs have allowed us to extrapolate content in response to queries based on data from search results.
Let’s talk about how it all works and where the SEO skillset evolves to account for it.
What is retrieval-augmented generation?
Retrieval-augmented generation (RAG) is a paradigm wherein relevant documents or data points are collected based on a query or prompt and appended as a few-shot prompt to fine-tune the response from the language model.
It’s a mechanism by which a language model can be “grounded” in facts or learn from existing content to produce a more relevant output with a lower likelihood of hallucination.

While the market thinks Microsoft introduced this innovation with the new Bing, the Facebook AI Research team first published the concept in May 2020 in the paper “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” presented at the NeurIPS conference. However, Neeva was the first to implement this in a major public search engine by having it power its impressive and highly specific featured snippets.
This paradigm is game-changing because, although LLMs can memorize facts, they are “information-locked” based on their training data. For example, ChatGPT’s information has historically been limited to a September 2021 information cutoff.
The RAG model allows new information to be considered to improve the output. This is what you’re doing when using the Bing Search functionality or live crawling in a ChatGPT plugin like AIPRM.
This paradigm is also the best approach to using LLMs to generate stronger content output. I expect more will follow what we’re doing at my agency when they generate content for their clients as the knowledge of the approach becomes more commonplace.
How does RAG work?
Imagine that you are a student who is writing a research paper. You have already read many books and articles on your topic, so you have the context to broadly discuss the subject matter, but you still need to look up some specific information to support your arguments.
You can use RAG like a research assistant: you can give it a prompt, and it will retrieve the most relevant information from its knowledge base. You can then use this information to create more specific, stylistically accurate, and less bland output. LLMs allow computers to return broad responses based on probabilities. RAG allows that response to be more precise and cite its sources.

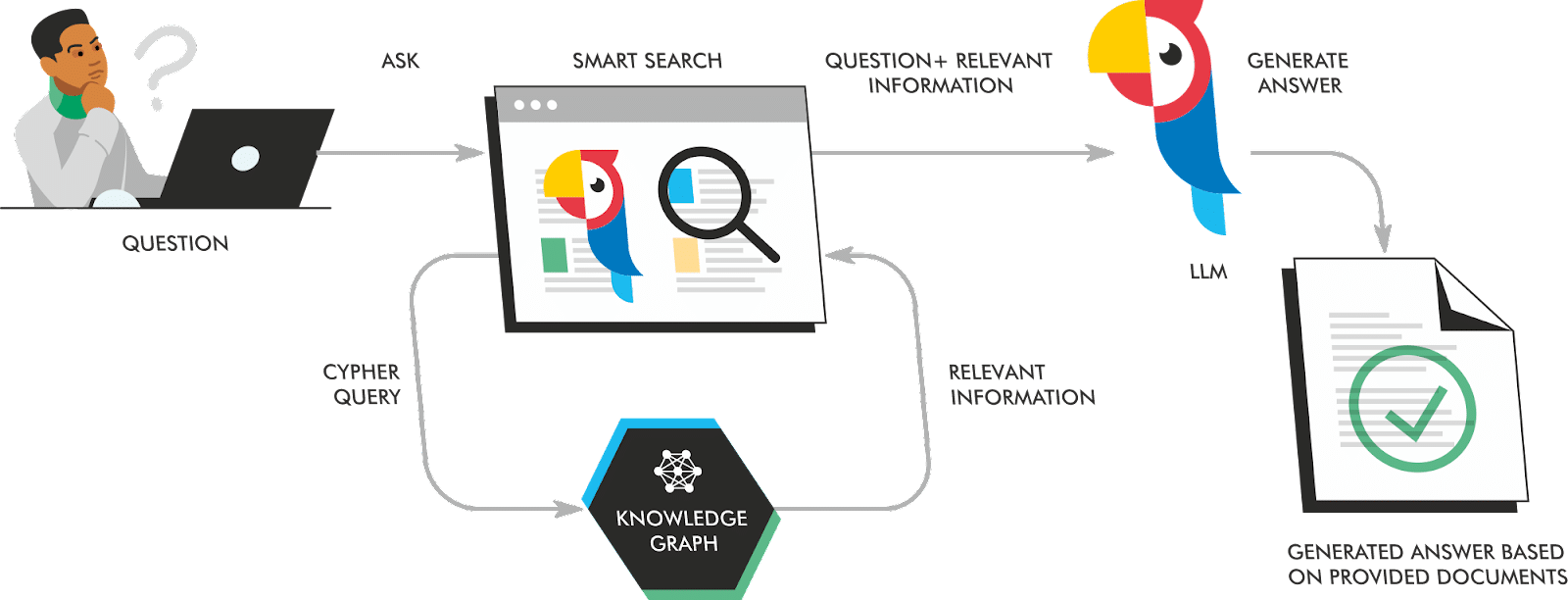
A RAG implementation consists of three components:
- Input Encoder: This component encodes the input prompt into a series of vector embeddings for operations downstream.
- Neural Retriever: This component retrieves the most relevant documents from the external knowledge base based on the encoded input prompt. When documents are indexed, they are chunked, so during the retrieval process, only the most relevant passages of documents and/or knowledge graphs are appended to the prompt. In other words, a search engine gives results to add to the prompt.
- Output Generator: This component generates the final output text, taking into account the encoded input prompt and the retrieved documents. This is typically a foundational LLM like ChatGPT, Llama2, or Claude.
To make this less abstract, think about ChatGPT’s Bing implementation. When you interact with that tool, it takes your prompt, performs searches to collect documents and appends the most relevant chunks to the prompt and executes it.
All three components are typically implemented using pre-trained Transformers, a type of neural network that has been shown to be very effective for natural language processing tasks. Again, Google’s Transformer innovation powers the whole new world of NLP/U/G these days. It’s difficult to think of anything in the space that doesn’t have the Google Brain and Research team’s fingerprints on it.
The Input Encoder and Output Generator are fine-tuned on a specific task, such as question answering or summarization. The Neural Retriever is typically not fine-tuned, but it can be pre-trained on a large corpus of text and code to improve its ability to retrieve relevant documents.
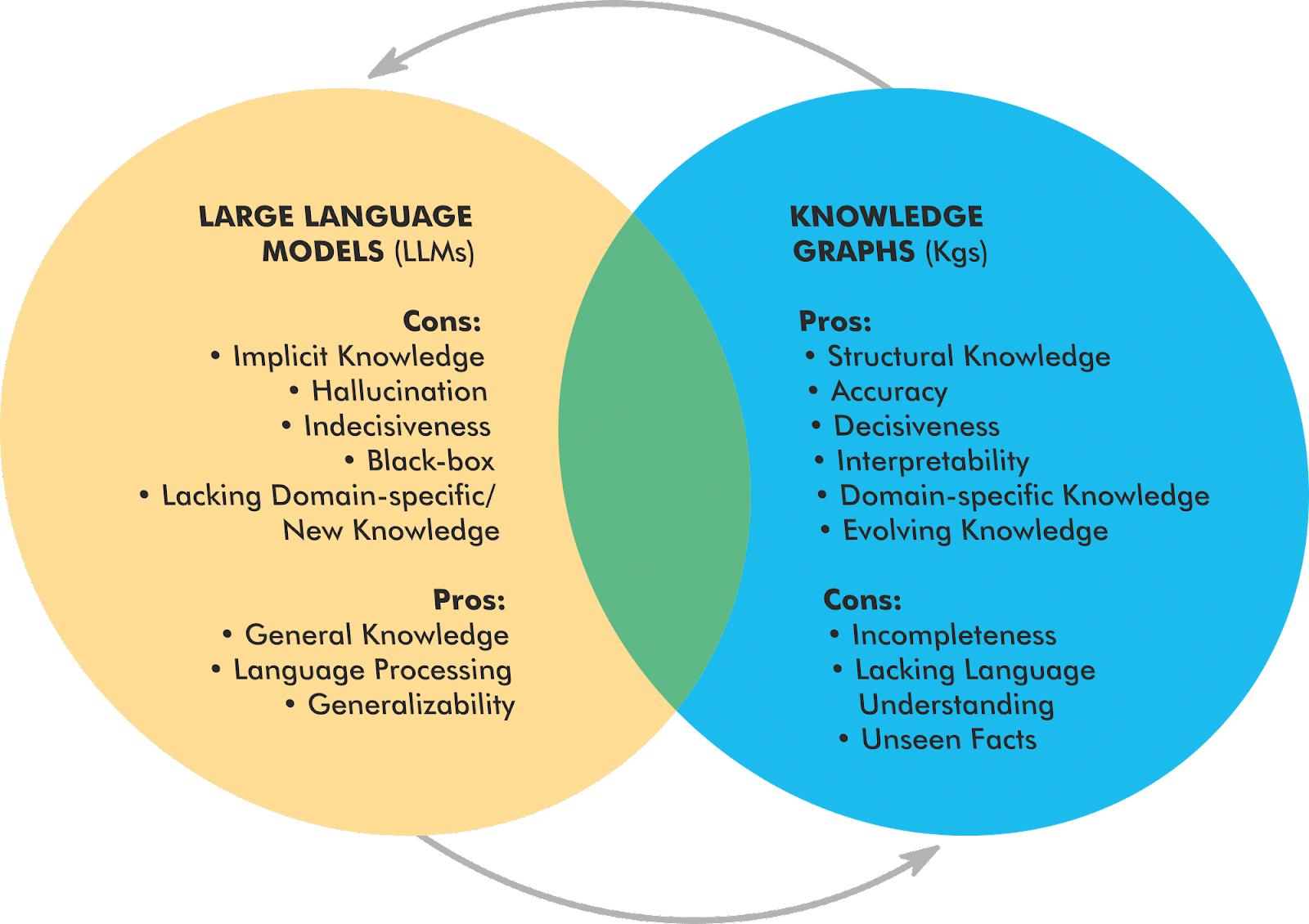
RAG is typically done using documents in a vector index or knowledge graphs. In many cases, knowledge graphs (KGs) are the more effective and efficient implementation because they limit the appended data to just the facts.
The overlap between KGs and LLMs shows a symbiotic relationship that unlocks the potential of both. With many of these tools using KGs, now is a good time to start thinking about leveraging knowledge graphs as more than a novelty or something that we just provide data to Google to build.
The gotchas of RAG
The benefits of RAG are pretty obvious; you get better output in an automated way by extending the knowledge available to the language model. What is perhaps less obvious is what can still go wrong and why. Let’s dig in:
Retrieval is the ‘make or break’ moment
Look, if the retrieval part of RAG isn’t on point, we’re in trouble. It’s like sending someone out to pick up a gourmet cheesesteak from Barclay Prime, and they come back with a veggie sandwich from Subway – not what you asked for.
If it’s bringing back the wrong documents or skipping the gold, your output’s gonna be a bit – well – lackluster. It’s still garbage in, garbage out.
It’s all about that data
This paradigm’s got a bit of a dependency issue – and it’s all about the data. If you’re working with a dataset that’s as outdated as MySpace or just not hitting the mark, you’re capping the brilliance of what this system can do.
Echo chamber alert
Dive into those retrieved documents, and you might see some déjà vu. If there’s overlap, the model’s going to sound like that one friend who tells the same story at every party.
You’ll get some redundancy in your results, and since SEO is driven by copycat content, you may get poorly researched content informing your results.
Prompt length limits
A prompt can only be so long, and while you can limit the size of the chunks, it may still be like trying to fit the stage for Beyonce’s latest world tour into a Mini-Cooper. To date, only Anthropic’s Claude supports a 100,000 token context window. GPT 3.5 Turbo tops out at 16,000 tokens.
Going off-script
Even with all your Herculean retrieval efforts, that doesn’t mean that the LLM is going to stick to the script. It can still hallucinate and get things wrong.
I suspect these are some reasons why Google did not move on this technology sooner, but since they finally got in the game, let’s talk about it.
What is Search Generative Experience (SGE)?
Numerous articles will tell you what SGE is from a consumer perspective, including:
- How to prepare for Google SGE: Actionable tips for SEO success
- How Google SGE will impact your traffic – and 3 SGE recovery case studies
- A tale of two snippets: What link attribution in SGE tells us about search
- Google SGE snapshot carousel: 4 winning SEO strategies in B2C, B2B
For this discussion, we’ll talk about how SGE is one of Google’s implementations of RAG; Bard is the other.
(Sidebar: Bard’s output has gotten a lot better since launch. You should probably give it another try.)

The SGE UX is still very much in flux. As I write this, Google has made shifts to collapse the experience with “Show more” buttons.
Let’s zero in on the three aspects of SGE that will change search behavior significantly:
Query understanding
Historically, search queries are limited to 32 words. Because documents were considered based on intersecting posting lists for the 2 to 5-word phrases in those terms, and the expansion of those terms,
Google did not always understand the meaning of the query. Google has indicated that SGE is much better at understanding complex queries.
The AI snapshot
The AI snapshot is a more robust form of the featured snippet with generative text and links to citations. It often takes up the entirety of the above-the-fold content area.
Follow-up questions
The follow-up questions bring the concept of context windows in ChatGPT into search. As the user moves from their initial search to subsequent follow-up searches, the consideration set of pages narrows based on the contextual relevance created by the preceding results and queries.
All of this is a departure from the standard functionality of Search. As users get used to these new elements, there is likely to be a significant shift in behavior as Google focuses on lowering the “Delphic costs” of Search. After all, users always wanted answers, not 10 blue links.
How Google’s Search Generation Experience works (REALM, RETRO and RARR)
The market believes that Google built SGE as a reaction to Bing in early 2023. However, the Google Research team presented an implementation of RAG in their paper, "Retrieval-Augmented Language Model Pre-Training (REALM)," published in August 2020.
The paper talks about a method of using the masked language model (MLM) approach popularized by BERT to do “open-book” question answering using a corpus of documents with a language model.
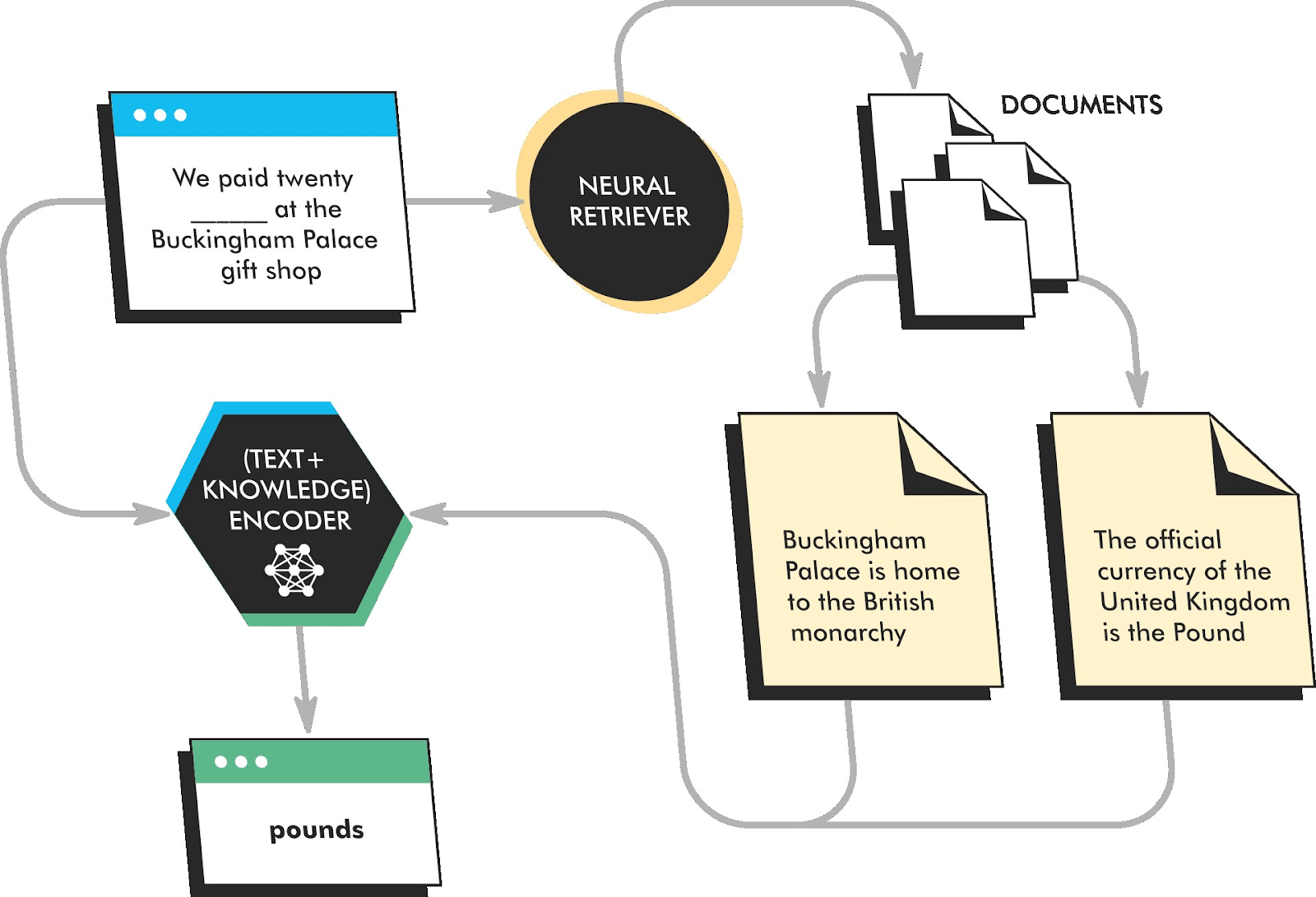
REALM identifies full documents, finds the most relevant passages in each, and returns the single most relevant one for information extraction.
During pre-training, REALM is trained to predict masked tokens in a sentence, but it is also trained to retrieve relevant documents from a corpus and attend to these documents when making predictions. This allows REALM to learn to generate more factually accurate and informative text than traditional language models.
Google’s DeepMind team then took the idea further with Retrieval-Enhanced Transformer (RETRO). RETRO is a language model that is similar to REALM, but it uses a different attention mechanism.
RETRO attends to the retrieved documents in a more hierarchical way, which allows it to better understand the context of the documents. This results in text that is more fluent and coherent than text generated by REALM.
Following RETRO, The teams developed an approach called Retrofit Attribution using Research and Revision (RARR) to help validate and implement the output of an LLM and cite sources.
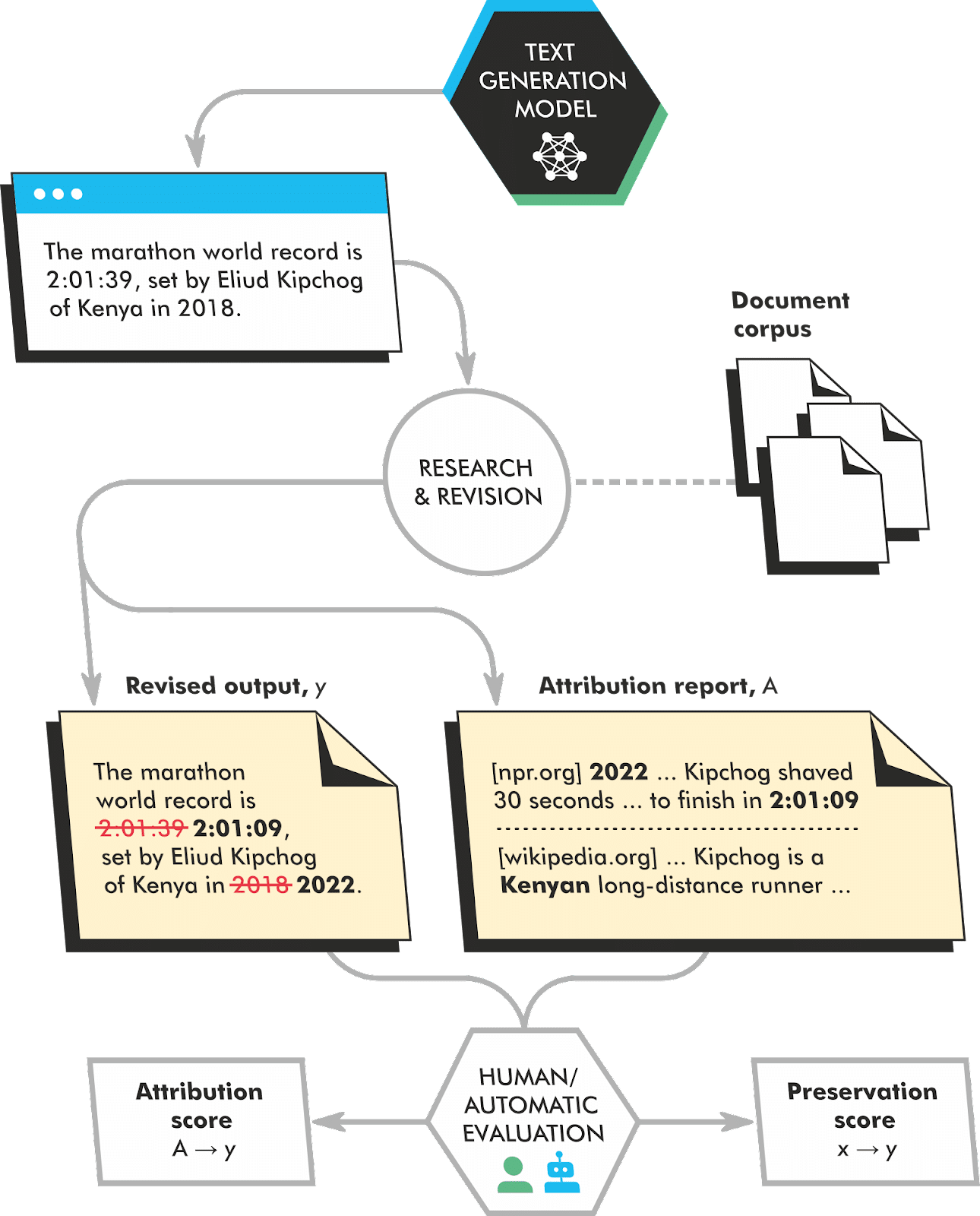
RARR is a different approach to language modeling. RARR does not generate text from scratch. Instead, it retrieves a set of candidate passages from a corpus and then reranks them to select the best passage for the given task. This approach allows RARR to generate more accurate and informative text than traditional language models, but it can be more computationally expensive.
These three implementations for RAG all have different strengths and weaknesses. While what’s in production is likely some combination of innovations represented in these papers and more, the idea remains that documents and knowledge graphs are searched and used with a language model to generate a response.
Based on the publicly shared information, we know that SGE uses a combination of the PaLM 2 and MuM language models with aspects of Google Search as its retriever. The implication is that Google’s document index and Knowledge Vault can both be used to fine-tune the responses.
Bing got there first, but with Google’s strength in Search, there is no organization as qualified to use this paradigm to surface and personalize information.
The threat of Search Generative Experience
Google’s mission is to organize the world’s information and make it accessible. In the long term, perhaps we’ll look back at the 10 blue links the same way we remember MiniDiscs and two-way pagers. Search, as we know it, is likely just an intermediate step until we arrive at something much better.
ChatGPT’s recent launch of multimodal features is the "Star Trek" computer that Google engineers have often indicated they want to be. Searchers have always wanted answers, not the cognitive load of reviewing and parsing through a list of options.
A recent opinion paper titled “Situating Search” challenges the belief, stating that users prefer to do their research and validate, and search engines have charged ahead.
So, here’s what is likely to happen as a result.
Redistribution of the search demand curve
As users move away from queries composed of newspeak, their queries will get longer.
As users realize that Google has a better handle on natural language, it will change how they phrase their searches. Head terms will shrink while chunky middle and long-tail queries will grow.
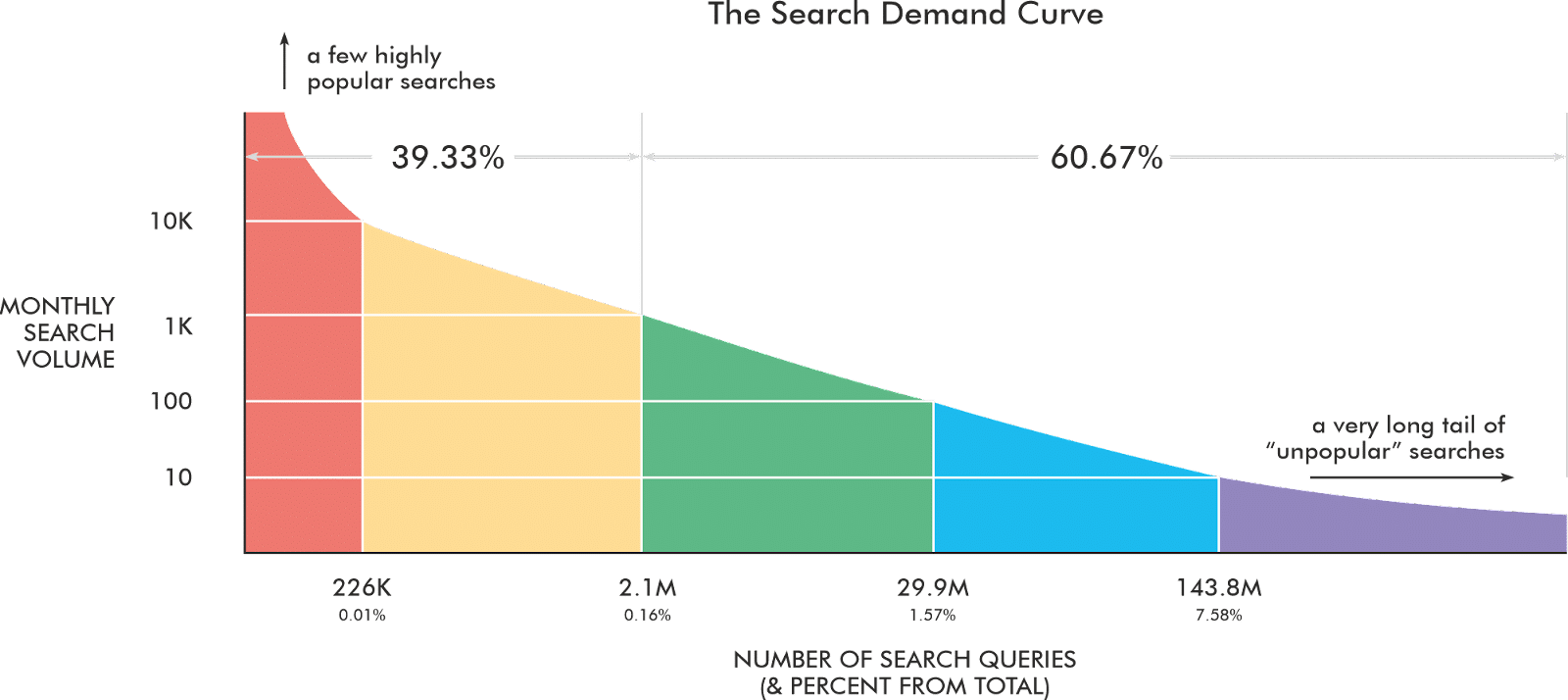
The CTR model will change
The 10 blue links will get fewer clicks because the AI snapshot will push the standard organic results down. The 30-45% click-through rate (CTR) for Position 1 will likely drop precipitously.
However, we currently don’t have true data to indicate how the distribution will change. So, the chart below is only for illustrative purposes.
Rank tracking will become more complex
Rank tracking tools have had to render the SERPs for various features for some time. Now, these tools will need to wait more time per query.
Most SaaS products are built on platforms like Amazon Web Service (AWS), Google Cloud Platform (GCP) and Microsoft Azure, which charge for compute costs based on the time used.
While rendered results may have come back in 1-2 seconds, now it may need to wait much longer, thereby causing the costs for rank tracking to increase.
Context windows will yield more personalized results
Follow-up questions will give users “Choose Your Own Adventure”-style search journeys. As the context window narrows, a series of hyper-relevant content will populate the journey where each individual would have otherwise yielded more vague results.
Effectively, searches become multidimensional, and the onus is on content creators to make their content fulfill multiple stages to remain in the consideration set.
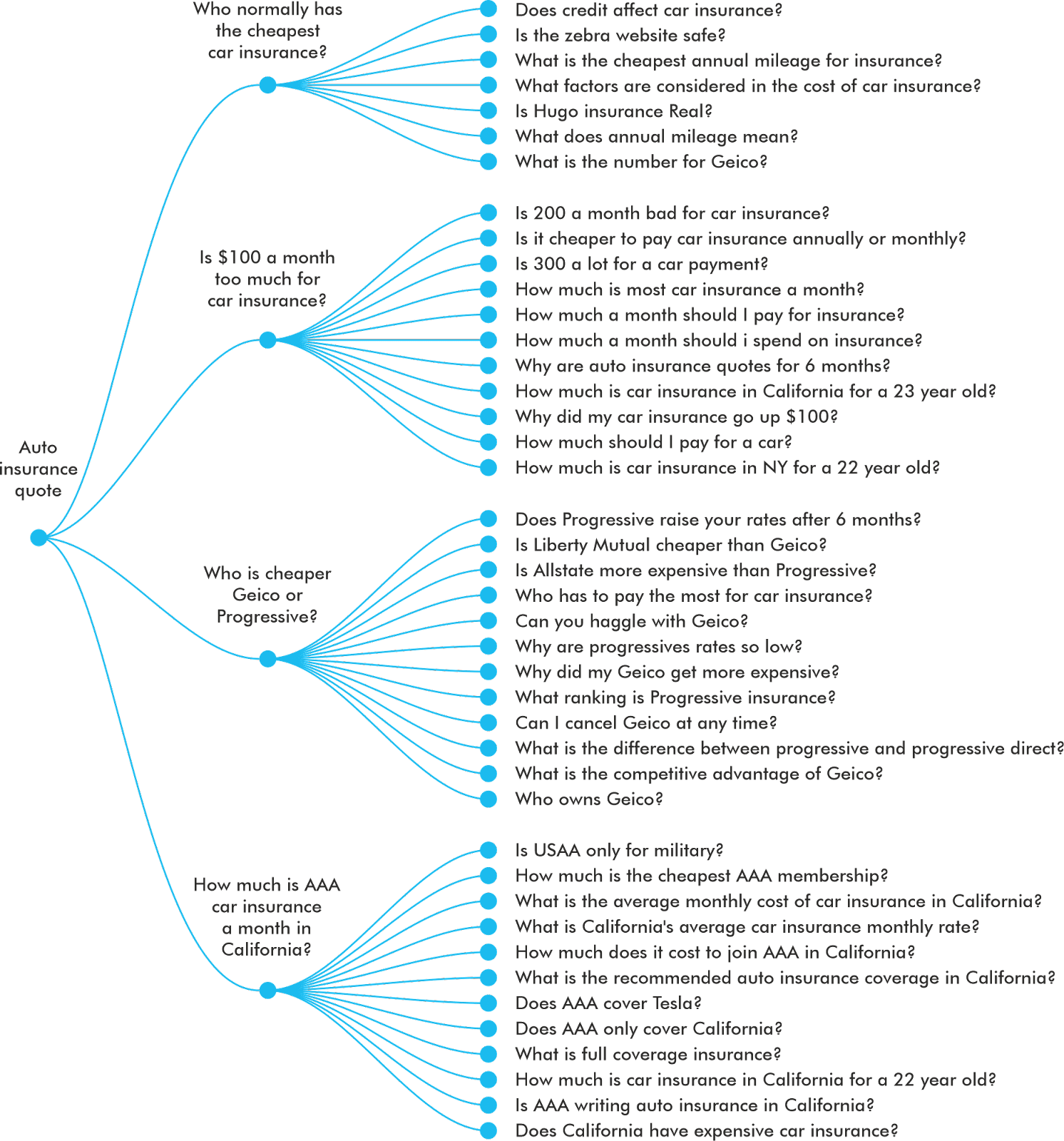
In the example above, Geico would want to have content that overlaps with these branches so they remain in the context window as the user progresses through their journey.
Determining your SGE threat level
We don’t have data on how user behavior has changed in the SGE environment. If you do, please reach out (looking at you, SimilarWeb).
What we do have is some historical understanding of user behavior in search.
We know that users take an average of 14.66 seconds to choose a search result. This tells us that a user will not wait for an automatically triggered AI snapshot with a generation time of more than 14.6 seconds. Therefore, anything beyond that time range does not immediately threaten your organic search traffic because a user will just scroll down to the standard results rather than wait.

We also know that, historically, featured snippets have captured 35.1% of clicks when they are present in the SERPs.
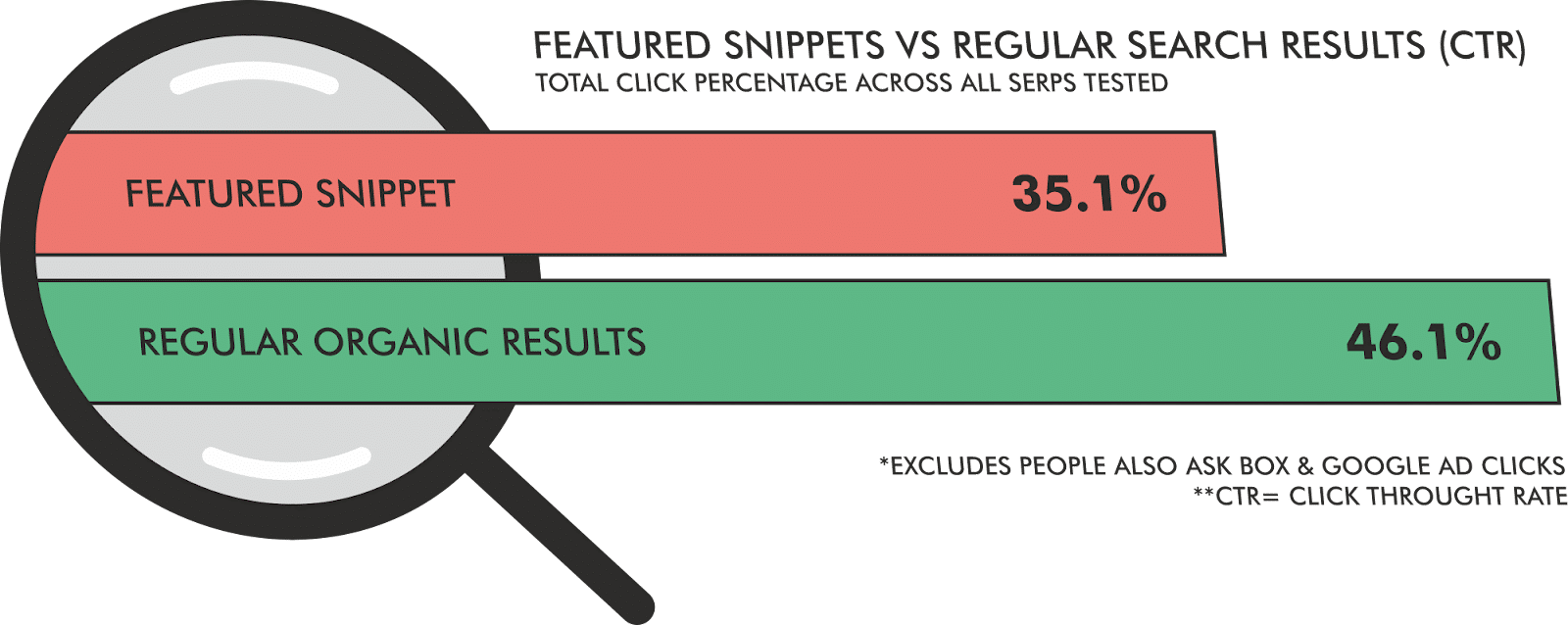
These two data points can be used to inform a few assumptions to build a model of the threat of how much traffic could be lost from this rollout.
Let’s first review the state of SGE based on available data.
The current state of SGE
Since there’s no data on SGE, it would be great if someone created some. I happened to come across a dataset of roughly 91,000 queries and their SERPs within SGE.
For each of these queries, the dataset includes:
- Query: The search that was performed.
- Initial HTML: The HTML when the SERP first loads.
- Final HTML: The HTML after the AI snapshot loads.
- AI snapshot load times: how long did it take for the AI snapshot to load.
- Autotrigger: Does the snapshot trigger automatically or do you have to click the Generate button?
- AI snapshot type: Is the AI snapshot informational, shopping, or local?
- Follow-up questions: The list of questions in the follow-up.
- Carousel URLs: The URLs of the results that appear in the AI snapshot.
- Top 10 organic results: The top 10 URLs to see what the overlap is.
- Snapshot status: Is there a snapshot or generate button?
- “Show more” status: Does the snapshot require a user to click “Show more?”
The queries are also segmented into different categories so we can get a sense of how different things perform. I don’t have enough of your attention left to go through the entirety of the dataset, but here are some top-level findings.
AI snapshots now take an average of 6.08 seconds to generate
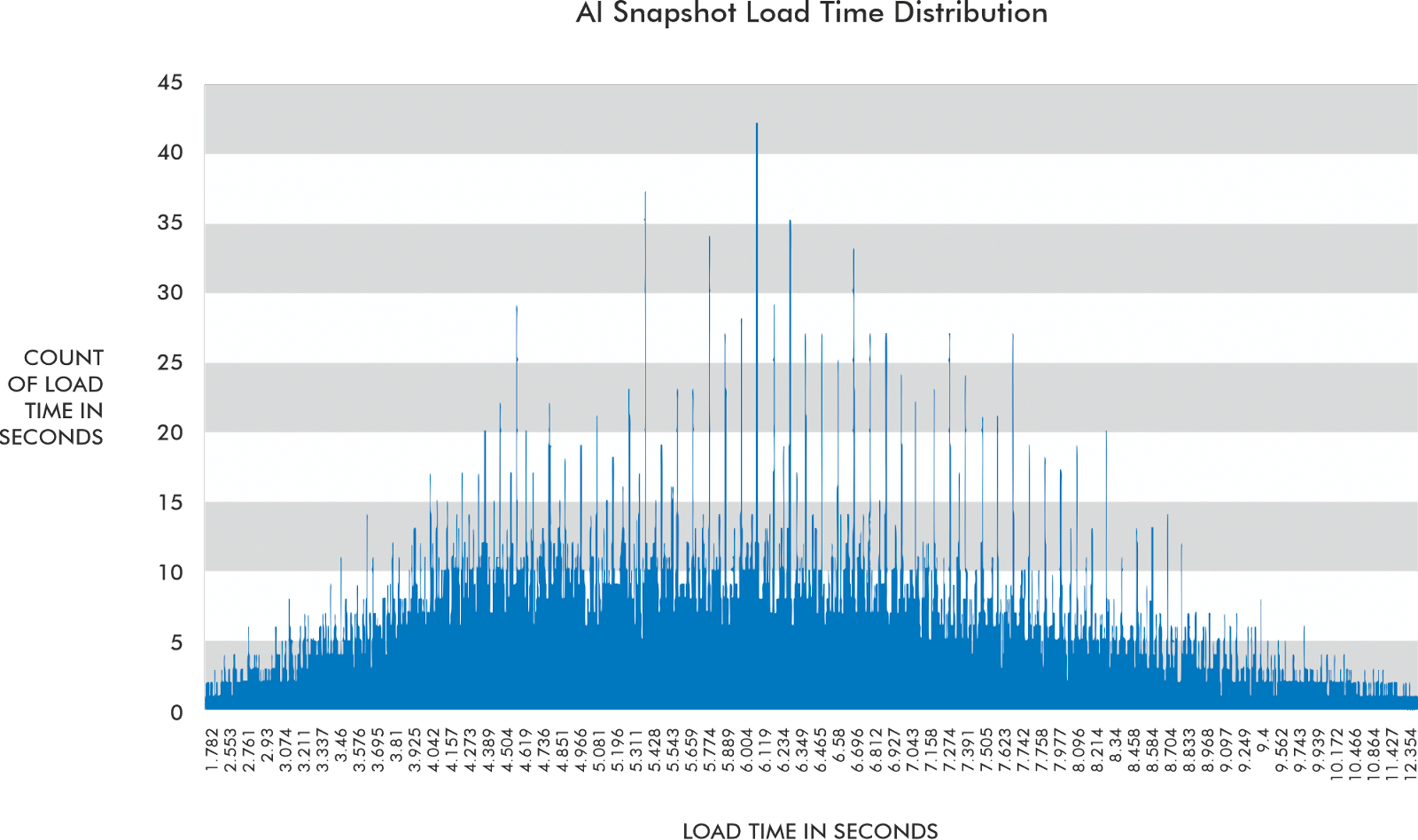
When SGE was first launched, and I started reviewing load times of the AI snapshot, it took 11 to 30 seconds for them to appear. Now I'm seeing a range of 1.8 to 17.2 seconds for load times. Automatically triggered AI snapshots load between 2.9 and 15.8 seconds.
As you can see from the chart, most load times are well below 14.6 seconds at this point. It’s pretty clear that the “10 blue link” traffic for the overwhelming majority of queries will be threatened.
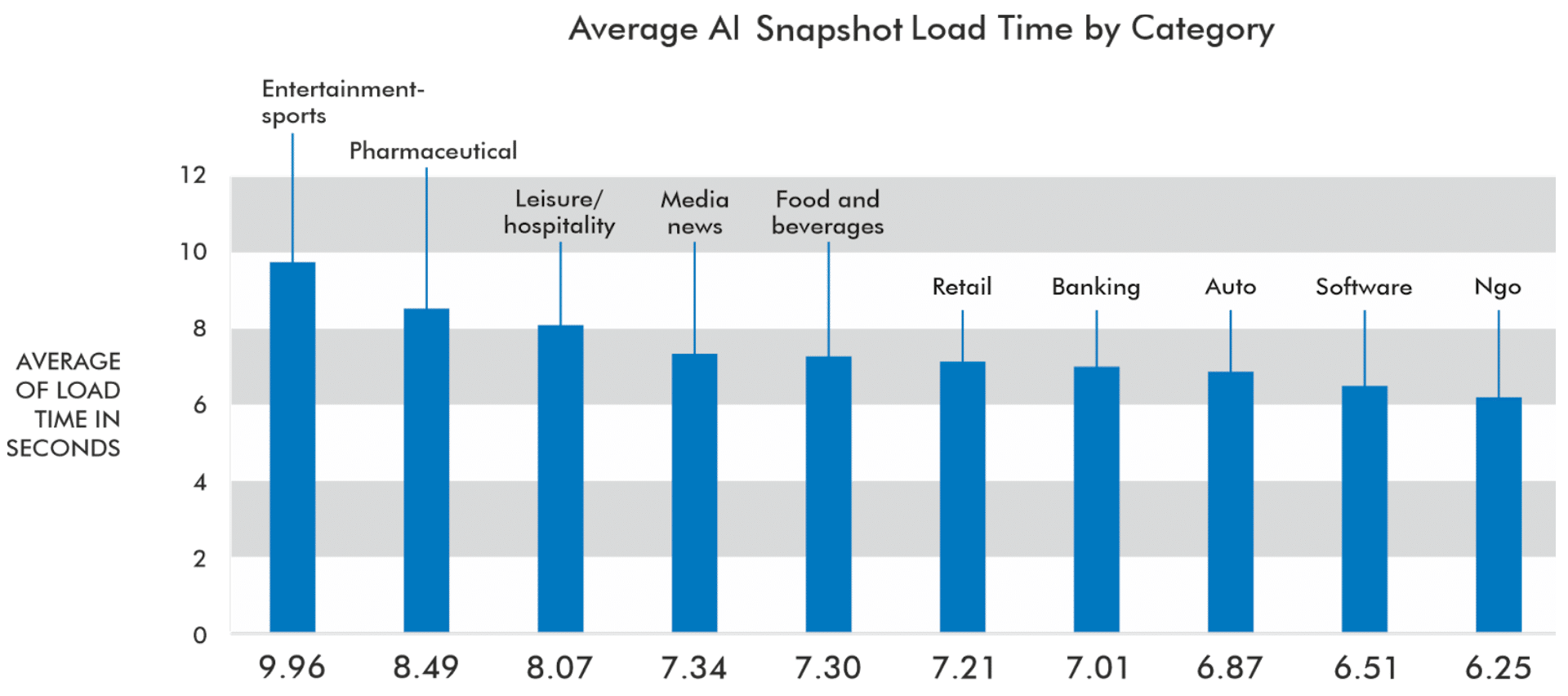
The average varies a bit depending on the keyword category. With the Entertainment-Sports category having a much higher load time than all other categories, this may be a function of how heavy the source content for pages typically is for each given vertical.
Snapshot type distribution
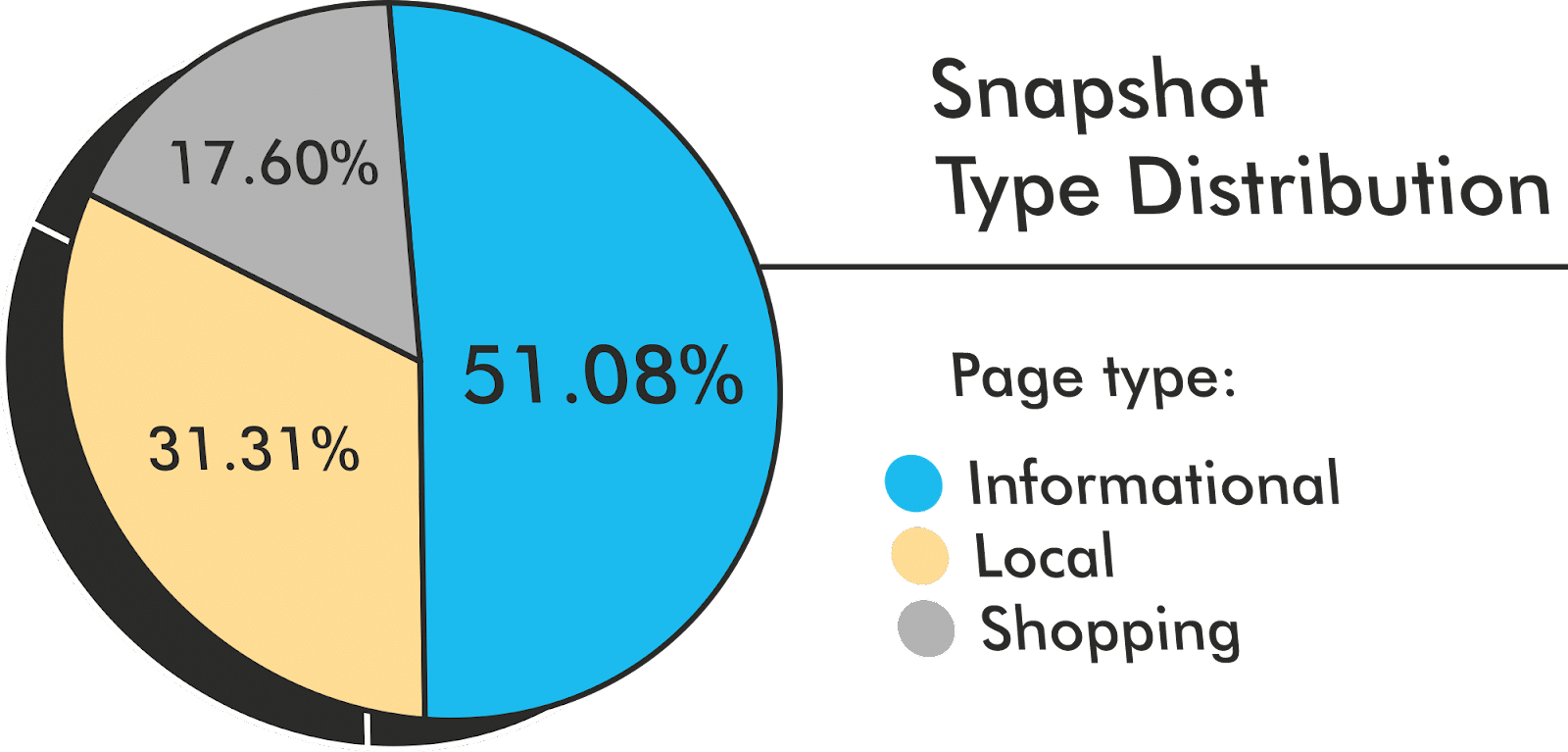
While there are many variants of the experience, I have broadly segmented the snapshot types into Informational, Local, and Shopping page experiences. Within my 91,000 keyword set, the breakdown is 51.08% informational, 31.31% local, and 17.60% shopping.
60.34% of queries did not feature an AI snapshot

In parsing the page content, the dataset identifies two cases to verify whether there is a snapshot on the page. It looks for the autotriggered snapshot and the Generate button. Reviewing this data indicates that 39.66% of queries in the dataset have triggered AI snapshots.
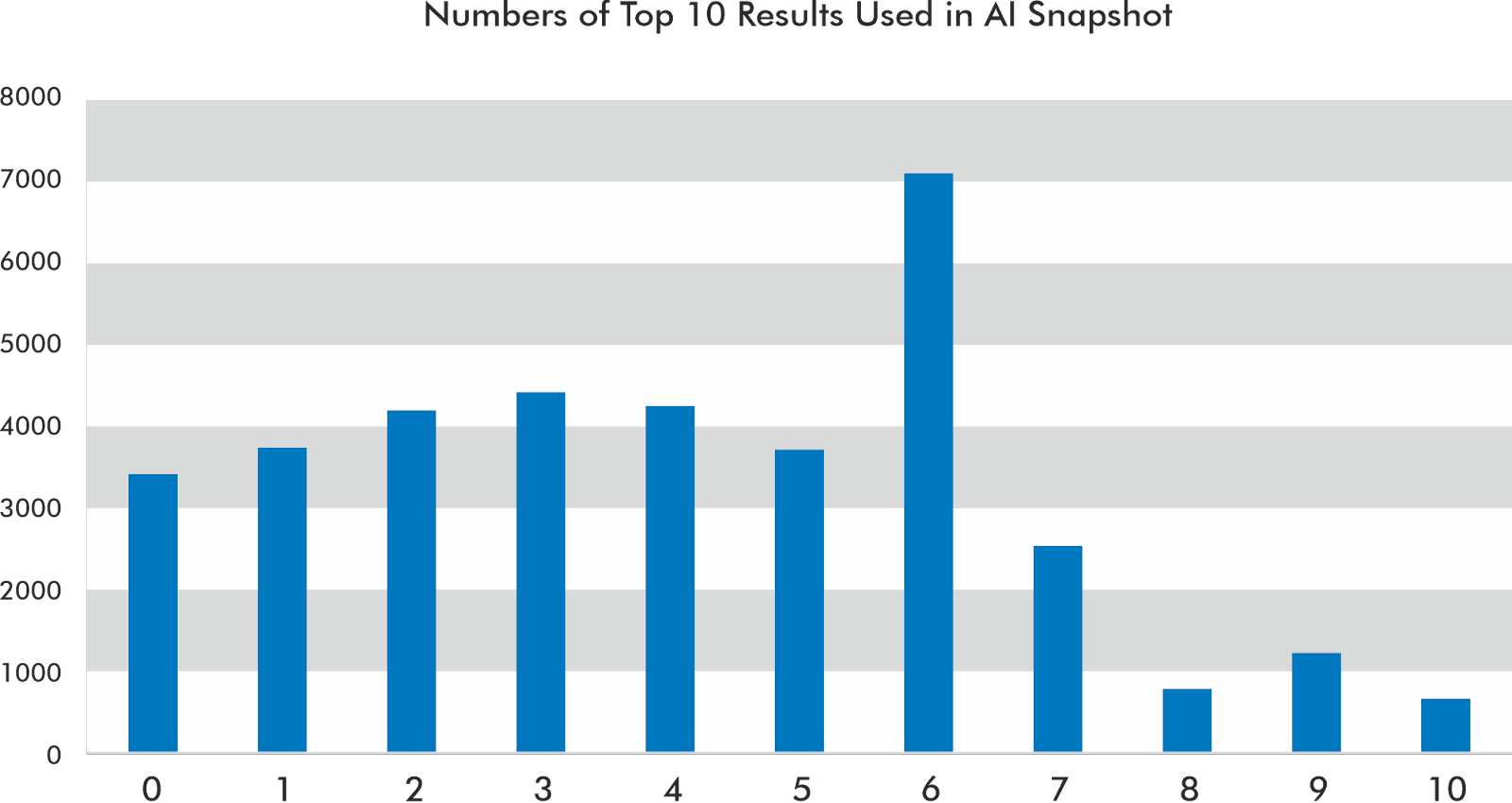
The top 10 results are often used but not always
In the dataset I’ve reviewed, Positions 1, 2, and 9 get cited the most in the AI snapshot’s carousel.
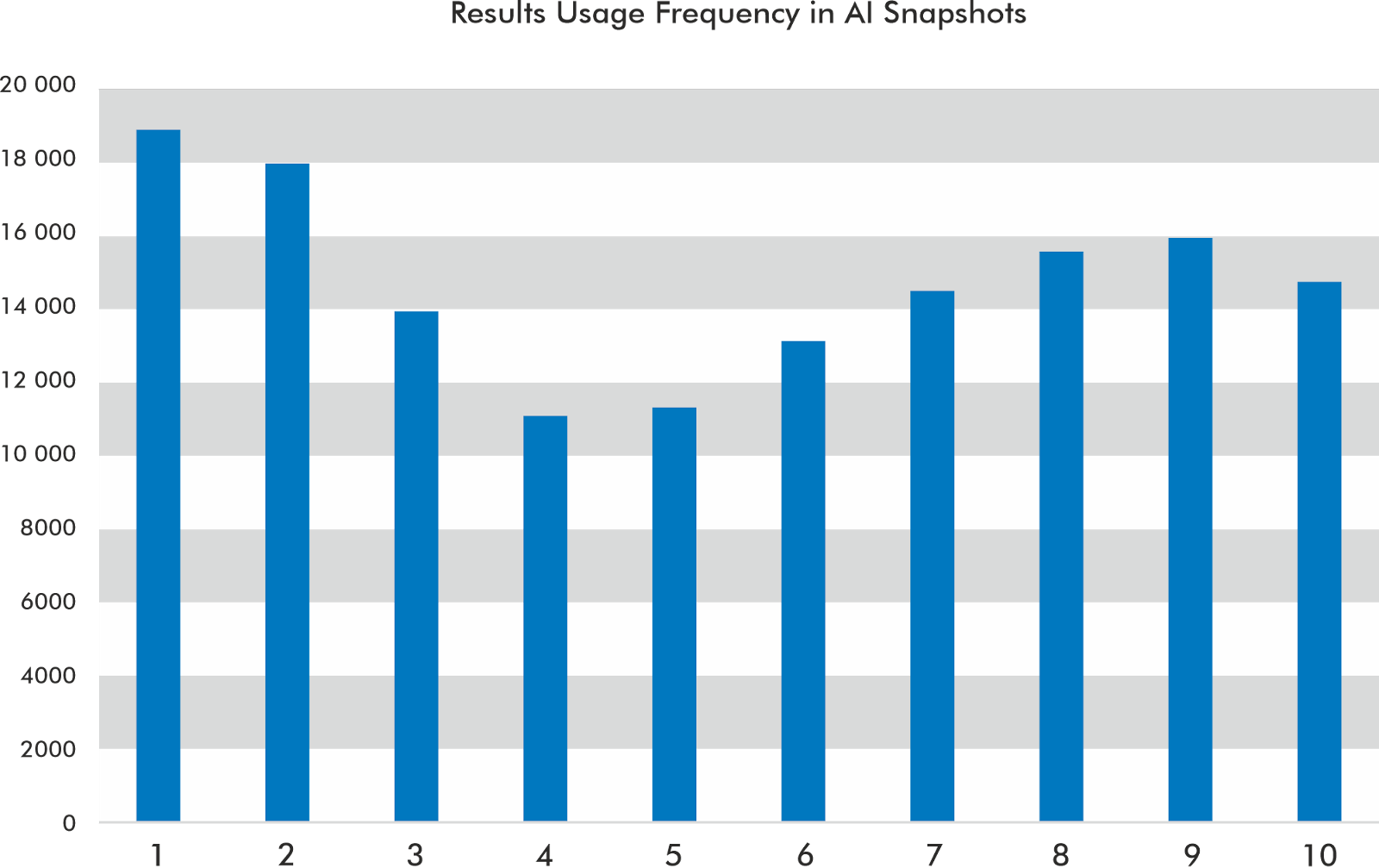
The AI snapshot most often uses six results out of the top 10 to build its response. However, 9.48% of the time, it does not use any of the top 10 results in the AI snapshot.
Based on my data, it rarely uses all the results from the top 10.
Highly relevant chunks often appear earlier in the carousel
Let’s consider the AI snapshot for the query [bmw i8]. The query returns seven results in the carousel. Four of them are explicitly referenced in the citations.

Clicking on a result in the carousel often takes you to one of the “fraggles” (the term for passage ranking links that the brilliant Cindy Krum coined) that drop you on a specific sentence or paragraph.

The implication is that these are the paragraphs or sentences that inform the AI snapshot.
Naturally, our next step is to try to get a sense of how these results are ranked because they are not presented in the same order as the URLs cited in the copy.
I assume that this ranking is more about relevance than anything else.

To test this hypothesis, I vectorized the paragraphs using the Universal Sentence Encoder and compared them to the vectorized query to see if the descending order holds up.
I’d expect the paragraph with the highest similarity score would be the first one in the carousel.

The results are not quite what I expected. Perhaps there may be some query expansion at play where the query I’m comparing is not the same as what Google might be comparing.
Either way, the result was enough for me to examine this further. Comparing the input paragraphs against the snapshot paragraph generated, the first result is the clear relevance winner.

The chunk used in the first result being most similar to the AI snapshot paragraph has held up across a bunch of these that I’ve spot-checked.
So, until I see evidence otherwise, ranking in the top 2 of the organic results and having the most relevant passage of content is the best way to get into the first slot in the carousel in SGE.
Calculating your SGE threat level
A lack of complete data is rarely a reason to not assess risk in a business environment. Many brands want an estimate of how much traffic they might lose when SGE becomes widely available.
To that end, we’ve built a model to determine traffic loss potential. The top-level equation is quite simple:
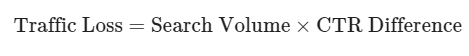
We only calculate this on keywords that have an AI snapshot. So, a better representation of the formula is as follows.

Adjusted CTR is where most of the magic happens, and getting here requires the “math to be mathin’,” as the kids say.
We need to account for the various ways that the SERP presents itself with respect to the page type, whether or not it triggers automatically, or whether it displays the “Show more” button.
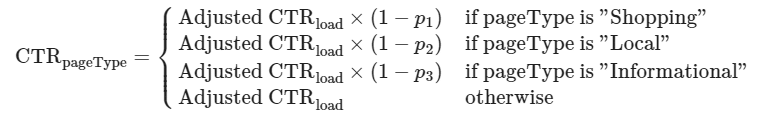
The short explanation is that we determine an adjusted CTR for each keyword based on the presence and load time of an AI snapshot, expecting the threat to be biggest for a shopping result because it’s a full-page experience.
Our adjusted CTR metric is a function of those parameters that are represented in a distribution factor.

The distribution factor is the weighted impact of the carousel links, citation links, shopping links, and local links in the AI snapshot.
This factor changes based on the presence of these elements and allows us to account for whether the target domain is present in any of these features.

For non-clients, we run these reports using the non-branded keywords where the traffic percentage is non-zero in Semrush and the vertical-specific CTR from Advanced Web Ranking’s CTR study.
For clients, we do the same using all keywords that drive 80% of clicks and their own CTR model in Google Search Console.
As an example, calculating this on those top traffic-driving keywords for Nerdwallet (not a client), the data indicates a “Guarded” threat level with a potential loss of 30.81%. For a site that primarily monetizes through affiliate revenue, that’s a sizable hole in their cash flow.

This has allowed us to develop threat reports for our clients based on how they currently show up in SGE. We calculate the traffic loss potential and score it on a scale of low to severe.
Clients find it valuable to rebalance their keyword strategy to mitigate losses down the line. If you’re interested in getting your own threat report, give us a shout.
Meet Raggle: A proof of concept for SGE
When I first saw SGE at Google I/O, I was eager to play with it. It wouldn’t become publicly available until a few weeks later, so I started building my own version of it. Around that same time, the good folks over at JSON SERP data provider AvesAPI reached out, offering me a trial of their service.
I realized I could leverage their service with an open-source framework for LLM apps called Llama Index to quickly spin up a version of how SGE might work.

So that’s what I did. It's called Raggle, and you can access it here.
Let me manage your expectations a bit, though, because I built this in the spirit of research and not with a team of 50,000 world-class engineers and PhDs. Here are its shortcomings:
- It’s very slow.
- It’s not responsive.
- It only does informational responses.
- It does not populate the follow-up questions.
- When my AvesAPI credits run out, new queries will stop working.
That said, I’ve added some easter eggs and additional features to help with understanding how Google is using RAG.
How Raggle works

Raggle is effectively a RAG implementation atop of a SERP API solution.
At runtime, it sends the query to AvesAPI to get back the SERP. We show the SERP HTML to the user as soon as it’s returned and then start crawling the top 20 results in parallel.
Once the content is extracted from each page, it’s added to an index in Llama Index with URLs, page titles, meta descriptions, and og:images as metadata for each entry.
Then, the index is queried with a prompt that includes the user’s original query with a directive to answer the query in 150 words. The best-resulting chunks from the vector index are appended to the query and sent to the GPT 3.5 Turbo API to generate the AI snapshot.
Creating the index from documents and querying it is only three statements:
index = VectorStoreIndex.from_documents(documents)
query_engine = CitationQueryEngine.from_args(
index,
# here we can control how many citation sources
similarity_top_k=5,
# here we can control how granular citation sources are, the default is 512
citation_chunk_size=155,
)
response = query_engine.query("Answer the following query in 150 words: " + query)Using the citation methods provided by the Llama Index, we can retrieve the blocks of text and their metadata to cite the sources. This is how I’m able to surface citations in the output in the same way that SGE does.
finalResponse["citations"].append({
'url': citation.node.metadata.get('url', 'N/A'),
'image': citation.node.metadata.get('image', 'N/A'),
'title': citation.node.metadata.get('title', 'N/A'),
'description': citation.node.metadata.get('description', 'N/A'),
'text': citation.node.get_text() if hasattr(citation.node, 'get_text') else
'N/A',
'favicon': citation.node.metadata.get('favicon', 'N/A'),
'sitename' : citation.node.metadata.get('sitename', 'N/A'),
})Go ahead and play around with it. When you click on the three dots on the right, it opens up the chunk explorer, where you can see the chunks used to inform the AI snapshot response.
In this proof-of-concept implementation, you’ll note how well the relevance calculation of the query versus the chunk aligns with the order in which results are displayed in the carousels.
We’re living in the future of search
I’ve been in the search space for nearly two decades. We’ve seen more change in the last 10 months than I’ve seen in the entirety of my career – and I say that having lived through the Florida, Panda and Penguin updates.
The flurry of change is yielding so many opportunities to capitalize on new technologies. Researchers in Information Retrieval and NLP/NLU/NLG are so forthcoming with their findings that we are getting more visibility into how things actually work.
Now is a good time to figure out how to build RAG pipelines into your SEO use cases.
However, Google is under attack on multiple fronts.
- TikTok.
- ChatGPT.
- The DOJ.
- The user perception of search quality.
- The deluge of generative AI content.
- Numerous versions of question-answering systems on the market.
Ultimately, all these threats to Google are threats to your traffic from Google.
The organic search landscape is changing in meaningful ways and becoming increasingly complex. As the forms by which users meet their information needs continue to fracture, we’ll move from optimizing for the web to optimizing for large language models and realizing the true potential of structured data in this environment.
Just like most opportunities on the web, the people who embrace these opportunities earliest will see outsized returns.
The post How Search Generative Experience works and why retrieval-augmented generation is our future appeared first on Search Engine Land.
from Search Engine Land https://ift.tt/s6MP3oN
via IFTTT
No comments:
Post a Comment