When strategically utilized, ChatGPT can surpass manual human effort in output quality.
No, the tools won’t write better content.
Instead, I believe a writer armed with this technology can craft optimized content that’s better aligned with Google’s ranking criteria.
By exploring various methods of content scoring and entity extraction, I aim to guide you toward maximizing the tools’ benefits.
“Beyond keywords: How entities impact modern SEO strategies” discussed how and why to include relevant entities across your website (i.e., topical map).
This article will focus on why and how to use entities to create better-ranking SEO content.
How are entity SEO and OpenAI related?
Before discussing how software optimizes entity use for search results, let’s understand the similarities between entity SEO and OpenAI’s ChatGPT.
Building blocks of language
At its most basic level, language is built around:
- Subjects: What (or whom) the sentence is about.
- Predicates: Says something about the subject.
For example, in the sentence “The cat sat on the mat,” “The cat” is the subject and “sat on the mat” is the predicate.
Both Google’s search engine and OpenAI’s ChatGPT are designed to understand the fundamental structure of language.
Semantic search engines focus on understanding content in a computationally efficient way.
ChatGPT goes a step further, using far more computation to generate content.
Semantic search engines
Google’s search engine identifies entities, which are essentially the subjects of sentences on a webpage.
It then uses the context around those entities to understand the predicates – or what is being said about those entities.
This enables Google to understand the page’s content and how it might be relevant to a user’s search query.
The relationships under consideration are depicted in Google’s Knowledge Graph.
When Google analyzes an article, it uses its Knowledge Graph to gain deeper insights.
It identifies relevant entities and predicates in the content, which allows it to discern what keyword searches the piece is most pertinent to.
OpenAI’s ChatGPT
On the other hand, ChatGPT uses its transformer model and embeddings to understand both subjects and predicates.
Specifically, the model’s attention mechanism allows it to understand the relationships between different words in a sentence, effectively understanding the predicate.
The embeddings, meanwhile, help the model understand the relationships and meanings of the words themselves, which includes understanding the subjects.

Despite their vast differences, ChatGPT and entity SEO share a common capability:
Recognizing entities and predicates relevant to a topic. This commonality underscores how vital entities are to our comprehension of language.
Despite the complexities, SEO professionals should focus their efforts on entities, subjects and their predicates.
So how do we use this new understanding to optimize our content?
Optimizing new content for entities
Google identifies entities and their predicates on a webpage. It also compares them across potentially relevant pages.
In essence, it’s like a matchmaker, trying to find the best match between a user’s search query and the content available on the web.
Given that Google’s algorithm is optimized for high-quality results, start your optimization process by examining the top 10 Google results.
This will give you insights into the attributes that Google favors for a given search term.
At our agency, we apply a framework to identify potential enhancements that can make our articles 10-20% better, which I’ll share below.
A framework that prioritizes the right aspects can illustrate the difference between your content and the highest-ranking material.
When creating content, we follow this framework and fulfill these priority items.
We set ourselves up for immediate success if we meet all these criteria.

Diving into the entity portion of the checklist
Think of it like this:
Imagine Google keeps track of how often certain entities and their predicates appear together.
It’s figured out which combinations are most important to users searching for specific topics.
As an SEO expert, your goal should be to include these key entities in your content, which you can identify by reverse engineering the top results that Google is showing you it already likes.
If your webpage includes the entities and predicates Google expects for a given user search, your content will earn a higher score.
We’ll touch on the exception of new entity relationships in a future discussion.
This is where tools that strategically utilize ChatGPT and NLP techniques come into play to help analyze the top 10 results.
Attempting this manually can be time-consuming and difficult because of the scale of data you’d have to consume.
Step 1: Extracting entities
To do this analysis, you’ll need to mimic Google’s native entity and predicate extraction processes and then turn your findings into a workable action plan/writer’s guide.
In technical jargon, this exercise is known as named entity recognition, and various NLP libraries have their own unique approaches.
Luckily, many content writing tools are available on the market that automate these steps.
However, before you blindly follow the recommendations of an SEO tool, it is helpful to understand what it will and won’t do well.
Named entity recognition (NER)
Think of NER as a two-step process: spotting and categorizing.
Spotting
- The first step is like a game of “I Spy.” The algorithm reads through the text word by word, looking for words or phrases that could be entities. It’s like someone reading a book and highlighting the names of people, places, or dates.
Categorizing
- Once the algorithm has spotted potential entities, the next step is to figure out what type of entity each one is. This is like sorting the highlighted words into different buckets: one for People, one for Locations, one for Dates, and so on.
Let’s consider an example. If we have the sentence: “Elon Musk was born in Pretoria in 1971.”
In the spotting step, the algorithm might identify “Elon Musk”, “Pretoria”, and “1971” as potential entities.
In the categorizing step, it would then classify “Elon Musk” as a Person, “Pretoria” as a Location, and “1971” as a Date.
The algorithm uses a combination of rules and machine learning models trained on large amounts of text.
These models have learned from examples what different types of entities look like, so they can make educated guesses when encountering new text.
Relation extraction (RE)
After NER identifies the entities in a text, the next step is to understand the relationships between these entities.
This is done through a process called relation extraction (RE). These relationships essentially act as the predicates that connect the entities.
In the context of NLP, these connections are often represented as triples, which are sets of three items:
- A subject.
- A predicate.
- An object.
The subject and object are typically the entities identified through NER, and the predicate is the relationship between them, identified through RE.

The concept of using triples to decipher and comprehend relationships is beautifully simplistic. We can grasp the core ideas presented with minimal computation, time, or memory.
It’s a testament to the nature of language that we get a good sense of what’s being said by zeroing in on just the entities and their predicates.
Remove all the extra words, and what you’re left with are the key components – a snapshot, if you will, of the relationships that the author is weaving.
Extracting relationships and representing them as triples is a crucial step in NLP.
It allows computers to understand the text’s narrative and the context around the identified entities, enabling more nuanced understanding and generation of human language.
Remember that Google is still a machine, and its understanding of language is different from human understanding.
Also, Google doesn’t have to write content but must balance computational demands. It can instead extract the minimal amount of information that achieves the goal of linking content to search query.
Step 2: Building a writer’s guide
We must mimic Google’s process of extracting entities and their relationships to generate a useful analysis and roadmap.
We must understand and employ these two key ideas in the top 10 search results. Fortunately, there are multiple ways to approach the roadmap building.
- We can rely on entity extraction
- We can extract keyword phrases.
The entity route
One route that can be tested is a methodology similar to tools like InLinks.
These platforms employ entity extraction on the top 10 results, likely utilizing Google Cloud’s NER API.
Next, they determine the minimum and maximum frequencies of the extracted entities within the content.
Based on your usage of these entities, they grade your content.
To determine successful entity usage within your material, these platforms often devise their own entity recognition algorithms.

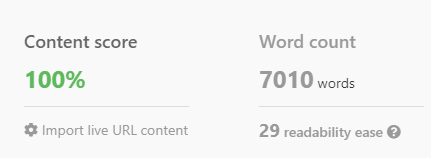
Pros and cons
This method is effective and can help you create more authoritative content. However, it overlooks a key aspect: relation extraction.
While we can match the usage of entities with the top-ranking articles, it’s challenging to verify if our content includes all the relevant predicates or relationships between these entities. (Note: Google Cloud doesn’t publicly share their relation extraction API.)
Another potential pitfall of this strategy is that it promotes the inclusion of every entity found in the top 10 articles.
Ideally, you’d want to encompass everything, but the reality is that some entities carry more weight than others.
Further complicating matters, search results often contain mixed intents, meaning some entities are only pertinent for articles catering to specific search intents.
For instance, the entity makeup of a product listing page will differ significantly from a blog post.
It can also be challenging for a writer to convert single-word entities into relevant topics for their content. Turning certain competitors on and off can help remedy these issues.
Don’t get me wrong, I’m a fan of these tools and use them as part of my analysis.
Every approach I’ll share here has its own advantages and drawbacks, all of which can enhance your content to some degree.
However, my aim is to present the diverse ways you can use technology and ChatGPT to optimize entities.
The keyword phrase route
Another strategy we’ve adopted in our tools involves extracting the most crucial keyword phrases from the top 10 competitors.
The beauty of keyword phrases lies in their transparency, making it easier for the end user to understand what they represent.
Plus, they typically capture the subject and predicate of key topics instead of just the subjects or entities.
However, one downside is that users often struggle to seamlessly incorporate these keywords into their content.
Instead, they tend to shoehorn in keywords, missing the essence of what the keyword phrase embodies.
Unfortunately, from a dev standpoint, measuring and scoring a writer based on their ability to capture a keyword phrase essence is difficult.
Therefore, developers must score based on the exact usage of a keyword phrase, which discourages the true intended behavior.
Another significant advantage of the keyword phrase approach is that keywords often serve as signposts for AI tools like ChatGPT, ensuring that the generative text model captures the key entities and their predicates (i.e., triples).
Lastly, consider the difference between being given a lengthy list of nouns versus a list of keyword phrases.
You might find it perplexing to weave a coherent narrative from a disconnected list of nouns as a writer.
But when you’re presented with keyword phrases, it’s much easier to discern how they might naturally interconnect within a paragraph, contributing to a more coherent and meaningful narrative.
What are the different approaches to extracting keyword phrases?
We’ve established that keyword phrases can effectively guide what topics you need to write about.
Still, it’s important to note that different tools in the market have varying approaches to extracting these crucial phrases.
Keyword extraction is a fundamental task in NLP that involves identifying important words or phrases that can summarize the content of a text.
There are several popular keyword extraction algorithms, each with its own strengths and weaknesses when capturing the entities on a page.
TF-IDF (Term frequency-inverse document frequency)
Although TF-IDF has been a popular discussion point among SEOs, it’s often misunderstood, and its insights are not always applied correctly.
Blindly adhering to its scoring can, surprisingly, detract from content quality.
TF-IDF weights each word in a document based on its frequency within the document and its rarity across all documents.
While it’s a simple and swift method, it doesn’t consider words’ context or semantic meaning.
What value can it provide
High-scoring words represent terms that are frequent on individual pages and infrequent across the entire collection of top-ranking pages.
On the one hand, these terms can be seen as markers of unique, distinguishing content.
They might reveal specific aspects or subtopics within your target keyword theme that are not thoroughly covered by competitors, allowing you to provide unique value.
However, the high-scoring terms can also be misleading.
TF-IDF can reveal a high score on terms uniquely important to specific ranking articles but doesn’t represent terms or topics generally important for ranking.
A basic example of this could be a company’s brand name. It could be used repeatedly in a single document or article but never in other ranking articles.
Including it in your content would make zero sense.
On the other hand, if you find terms with lower TF-IDF scores that appear consistently across high-ranking pages, these could indicate crucial “baseline” content that your page should contain.
They might not be unique, but they could be necessary for relevance to the given keyword or topic.
Note: TF-IDF represents many strategies, but additional mathematics can be applied in variations. These include algorithms like BM25 to introduce saturation points or calculations of diminishing returns.
Additionally, TF-IDF can be vastly improved, and often is, by retroactively showing for each term the percentage of top 10 pages that include the word. Here, the algorithm helps you identify noteworthy terms but then helps you better understand the “baseline” terms by showing the extent to which the top 10 ranking terms share the terms.
RAKE (Rapid automatic keyword extraction)
RAKE considers all phrases as potential keywords, which can be useful for capturing multi-word entities.
However, it doesn’t consider the order of words, which can lead to nonsensical phrases.
Applying the RAKE algorithm to each of the top 10 pages separately will produce a list of key phrases for each page.
The next step is to look for overlap – key phrases that appear on multiple top-ranking pages.
These common phrases may indicate topics of particular importance that search engines expect to see in relation to your target keyword.
By integrating these phrases into your own content (in a meaningful and natural way), you could potentially increase your page’s relevance and, thereby, its ranking for the targeted keyword.
However, it’s important to note that not all shared phrases are necessarily beneficial. Some may be common because they are generic or broadly associated with the topic.
The goal is to find those shared phrases that carry significant meaning and context related to your specific keyword.
All keyword extraction techniques can be improved by allowing you to use your brain to turn competitors or keywords on or off.
The ability to turn competitors and specific keywords on and off will help remedy the aforementioned problems.
Competitors
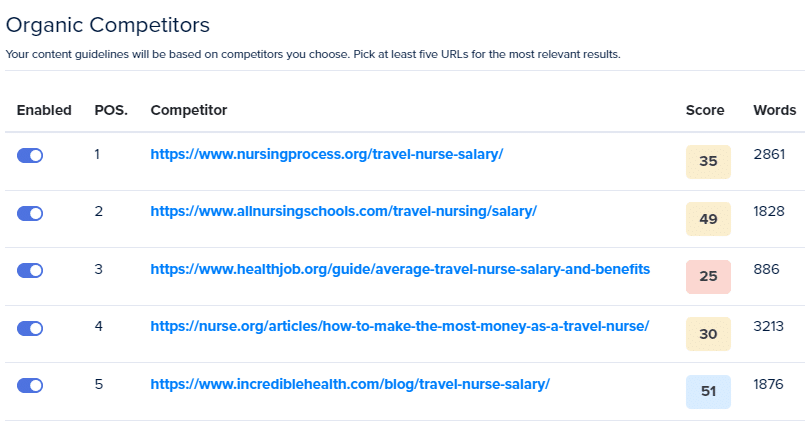
Keywords
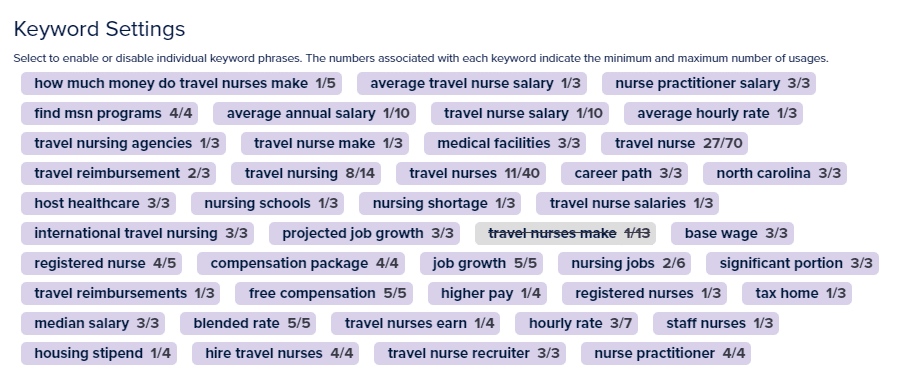
This approach essentially provides a way to combine the strengths of both RAKE (identifying key phrases within individual documents) and a more TF-IDF-like strategy (considering the importance of terms across a collection of documents).
By doing so, you can harness a more holistic understanding of the content landscape for your target keyword, guiding you to create unique and relevant content.
YAKE (Yet another keyword extractor)
Lastly, YAKE considers the frequency of words and their position in the text.
This can help identify important entities that appear at the beginning or end of a document.
However, it may miss important entities that appear in the middle.
Each algorithm scans the text and identifies potential keywords based on various criteria (e.g., frequency, position, semantic similarity).
They then assign a score to each potential keyword; the highest-scoring keywords are selected as the final.
These algorithms can effectively capture entities, but there are limitations.
For example, they may miss rare entities or don’t appear as keywords in the text. They may also struggle with entities with multiple names or that are referred to in different ways.
In summary, keywords provide a couple of enhancements over straight NER.
- They are easier for a writer to understand.
- They capture both the predicates and the entities.
- As we will see in the next section, they operate as better guideposts for AI to write entity-optimized content.
OpenAI
ChatGPT and OpenAI are truly game-changers in SEO.
To unlock its full potential, it needs a well-informed SEO expert to steer it along the right path and a meticulously constructed entity map to guide it on relevant topics to write about.
Consider a scenario:
You might have realized you can head to ChatGPT and ask it to write an article about almost any subject, and it will readily comply.
However, the question is, will the resulting article be optimized to rank for a keyword?
We must draw a clear distinction between general content and search-optimized content.
When AI is left to its own devices to write your content, it tends to generate an article that appeals to a regular reader.
However, content optimized for SEO dances to a different tune.
Google tends to favor content that’s scannable, includes definitions and necessary background knowledge, and fundamentally offers plenty of hooks for readers to find answers to their search queries.
ChatGPT, being powered by transformer architecture, tends to produce content based on observed frequency and patterns in the data it was trained on. A small fraction of this data consists of top-ranking Google articles.
In contrast, as time passes, Google adapts its search results to their effectiveness for a user – essentially survival of the fittest content pieces.
The entities found in these enduring articles are vital to emulate as foundational content, which tends to diverge significantly from what ChatGPT produces right out of the box.
The key takeaway is that there’s a difference between content that’s a winner from a readability standpoint and content that’s a winner in a Google environment. In the world of web content, utility trumps all.
As shown long ago by Nielsen, scannability reigns supreme.
User’s prefer scanning web content over reading from top to bottom. This behavior usually follows an F-shaped pattern. Writing content that does well in search should focus on being easily scannable vs. purely written to be read from top to bottom.
ChatGPT out of the box
Let’s observe how ChatGPT performs right out of the box, using Noble and Inlinks for scoring.
Even with a meticulously crafted prompt, without the context of what’s working on the first page of Google, ChatGPT often misses the mark, producing content unlikely to compete.
I prompted ChatGPT to write an article on “How much do travel nurses make per hour.”
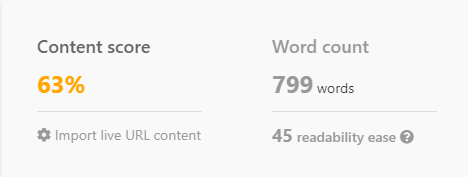

When paired with SEO analysis
However, ChatGPT can exhibit its true power when combined with SERP analysis and keywords crucial for ranking.
By asking ChatGPT to include these terms, the AI is guided toward generating topically relevant content.


Here are a few important points to remember
While ChatGPT will incorporate many key entities relevant to a topic, using tools that analyze SERP results can significantly enhance the mix of entities in your content.
Also, these differences can be more pronounced depending on the subject matter, but if you run this experiment more times, you’ll find this is a consistent trend.
Approaches based on keywords fulfill two requirements simultaneously:
- Ensure the inclusion of the most critical entities.
- Provide a more rigorous grading system since they encompass both predicates and entities.
Additional insights
ChatGPT might have difficulties achieving the necessary content length on its own.
The further the page’s intent deviates from blog-style posts, the more noticeable the performance gap becomes between ChatGPT and SEO tools that use ChatGPT separately.
Despite the AI’s capabilities, it’s essential to remember the human factor. Not all pages should be analyzed due to mixed search results.
Additionally, keyword extraction techniques aren’t foolproof, and edge cases can yield irrelevant proper nouns that might still make it through the scoring system.
Therefore, the optimal balance between human intervention and AI involves manually disabling any competing site with a different intent and combing your keyword list to prune any glaringly wrong keywords.
Last steps: Taking it one step further
The methods we’ve discussed are a starting point, allowing you to create content that covers a broader range of entities and their predicates than any of your competitors.
By following this approach, you’re writing content that mirrors the characteristics of pages that Google already favors.
But remember, this is just a jumping-off point. These competing pages have likely been around for some time and may have accrued more backlinks and user metrics.
If your goal is to outperform them, you’ll need to make your content stand out even more.
As the web becomes increasingly saturated with AI-generated content, it’s reasonable to speculate that Google might start favoring websites it trusts to establish new entity relationships. This will likely shift how content is evaluated, emphasizing original thought and innovation more.
As a writer, this means going beyond merely incorporating the subjects covered by the top 10 results. Instead, ask yourself: what unique perspective can you offer missing from the current top 10?
It’s not just about the tools. It’s about us, the strategists, the thinkers, the creators.
It’s about how we wield these tools and how we balance the computational prowess of software with the creative spark of the human mind.
Just like in the world of chess, it’s the combination of machine precision and human ingenuity that truly makes a difference.
So, let’s embrace this new era of SEO, where we’re creating content and crafting experiences that resonate with our audience and stand out in the vast digital landscape.
The post How ChatGPT can help you optimize your content for entities appeared first on Search Engine Land.
from Search Engine Land https://ift.tt/3duaset
via IFTTT
No comments:
Post a Comment